
Do OpenAI's New Reasoning Models (o1 Series) Differ Politically from Their Predecessors?
How the o1 models that leverage inference time compute compares to GPT-4o and GPT-3.5 on political orientation tests
In previous analyses, I have documented how state-of-the-art language models (LLMs) tend to exhibit left-leaning political preferences when subjected to popular political orientation tests. This pattern has been consistent across several generations of models and providers, including OpenAI’s GPT-3.5 and GPT-4, Google’s Gemini or Meta’s Llama series. More recent findings indicate that these predilections are also present in latent form within the open-ended, long-form text generated by LLMs.
Recently, OpenAI introduced a new paradigm of LLMs known as the o1 series. These models employ a reasoning-based approach, utilizing additional inference-time computation to enhance the quality of responses. In essence, o1 models are designed to "think" before responding, generating an extended chain of thought internally before producing answers. This reasoning capability enables the o1 series to outperform previous models like GPT-4o on challenging benchmarks in physics, chemistry, biology, coding, and mathematics. However, this improvement comes at a cost—o1 models are approximately 30 times slower and six times more expensive to run than GPT-4o (source).
Given these advancements, I was curious whether the reasoning step of the o1 models might influence the political preferences they manifest when answering to questions with political connotations.
Results and Observations
I administered four popular political orientation tests five times to each of the o1 models and their predecessors (GPT-4o, GPT-4o-mini and GPT-3.5). I then averaged the results of each model/test administration. The results are displayed in the figure below:
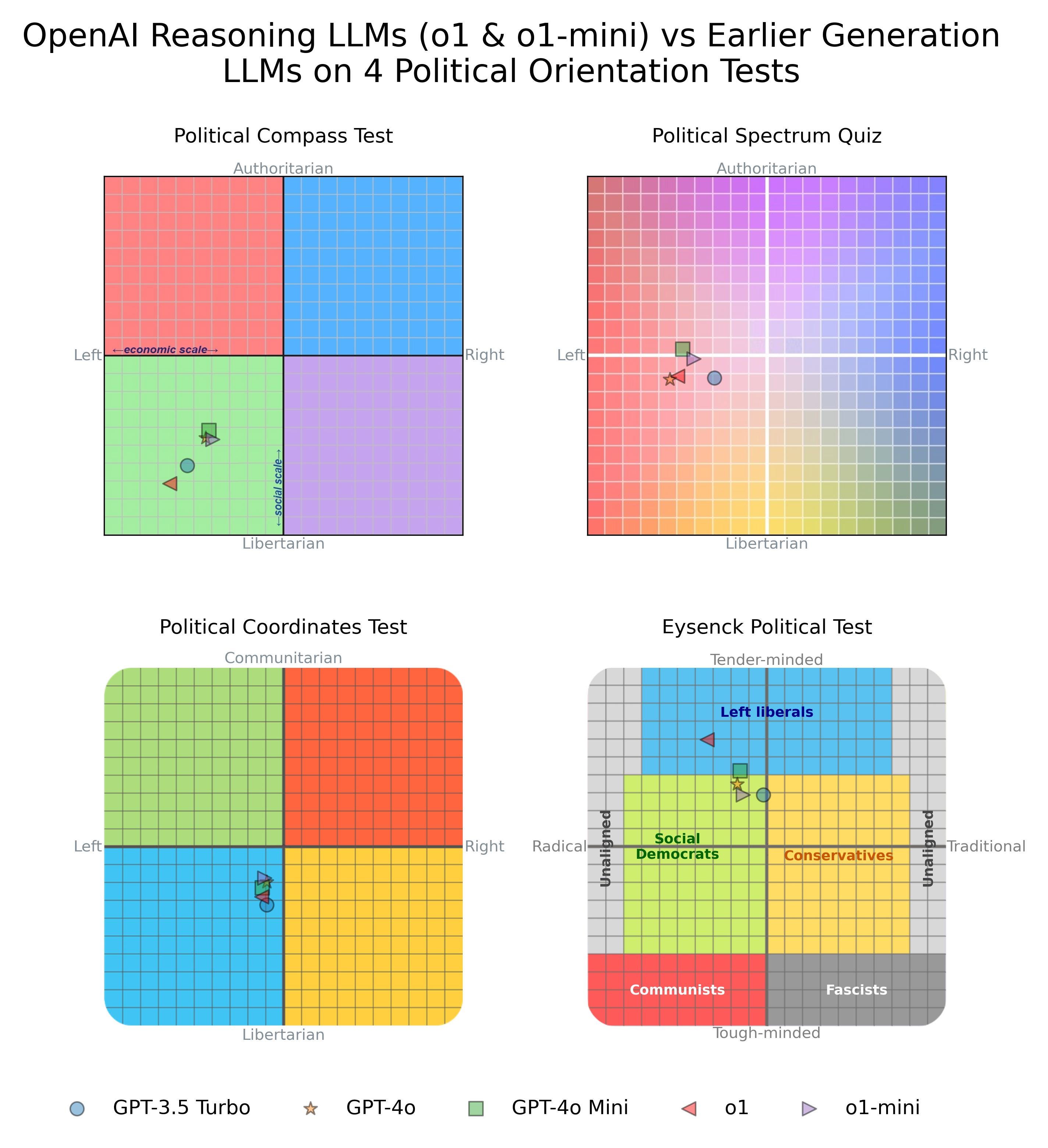
The results reveal that the political preferences of the o1 series models remain largely consistent with those of their predecessors. Despite the introduction of a reasoning step, the overall political alignment of these models has not significantly changed.
This outcome cannot be attributed to the o1 models failing to utilize their reasoning capabilities. On average, the o1 model used 1,178 internal reasoning tokens before answering each test question, while the o1-mini model used 514 internal reasoning tokens prior to choosing an answer from the political orientation test. This indicates that the reasoning step was actively employed, yet it did not alter the political orientation exhibited by the models when answering questions with political connotations.
Conclusion
The findings suggest that the "reasoning" step incorporated into OpenAI's o1 series models does not appear to affect their political preferences. Despite the significant enhancements in reasoning and problem-solving, the models' political inclinations remain aligned with those of earlier generations.
These insights raise intriguing questions about the extent to which reasoning and political orientation are intertwined in LLMs. As models continue to evolve, further exploration into this relationship could provide deeper understanding of how LLMs interpret and respond to politically charged content.
Would be interesting to see results for DeepSeek and other Chinese models.
This might be because these newer models reflect the biases inherent in the training data, which is also prepared by the same left leaning fellow who did a similar job with the previous LLMs.
They call this GIGO -- garbage in, garbage out.
In essence, each LLM is a pet project to be consumed by an audience sampled from the same population as the designers. Because they are echo chambers, they will reinforce prior beliefs backed by sources real and imagined.