


Measuring Political Preferences in AI Systems – An Integrative Approach

Recent studies have suggested that large language models (LLMs)—like OpenAI’s ChatGPT or Google’s Gemini—might exhibit political biases. These studies typically rely on standardized political orientation tests to assess such biases. However, forcing AI systems to select one from a predefined set of allowed responses to a query does not accurately reflect typical users’ interactions with AI systems. Political bias in LLMs is likely to manifest in more nuanced ways in long-form, open-ended AI-generated content. In any case, any method of probing for political bias in AI systems is likely amenable to criticism.
In a new report, I address these challenges by combining four different methodologies into a single aggregated score of AI systems political bias. This integrative strategy mitigates the individual weaknesses of each approach and perhaps offers a more robust measurement of political bias in AI.
To understand the analysis below, it is important to be aware of 3 different categories of LLMs:
Base LLMs (Foundation LLMs): Models pretrained from scratch to predict the next token in a sequence using a feed of raw web documents. Base LLMs tend not to follow user instructions well, and thus are not typically deployed for interacting with humans. Instead, base models serve as a starting point for developing conversational LLMs.
Conversational LLMs: Models derived from pretrained base models by fine-tuning them with datasets created by human contractors showing the models how to respond to user instructions and optionally some form of reinforcement learning or direct preference of optimization. These conversational LLMs are what most people interact with when using an LLM, as they are better at producing relevant responses that align with user expectations.
Ideologically Aligned LLMs: Experimental conversational LLMs which undergo an additional fine-tuning steps that uses politically biased training data to steered the model into a target location of the political spectrum. For contrast, I include in the analysis below two ideologically aligned LLMs: Leftwing GPT and Rightwing GPT.
Comparing AI-generated text with the language used by U.S. Congress legislators
Previous research on U.S. media political slant found that left-leaning news outlets more frequently used partisan terms favored by Democrats in the Congressional record, while right-leaning news outlets emphasized partisan terms favored by Republicans.
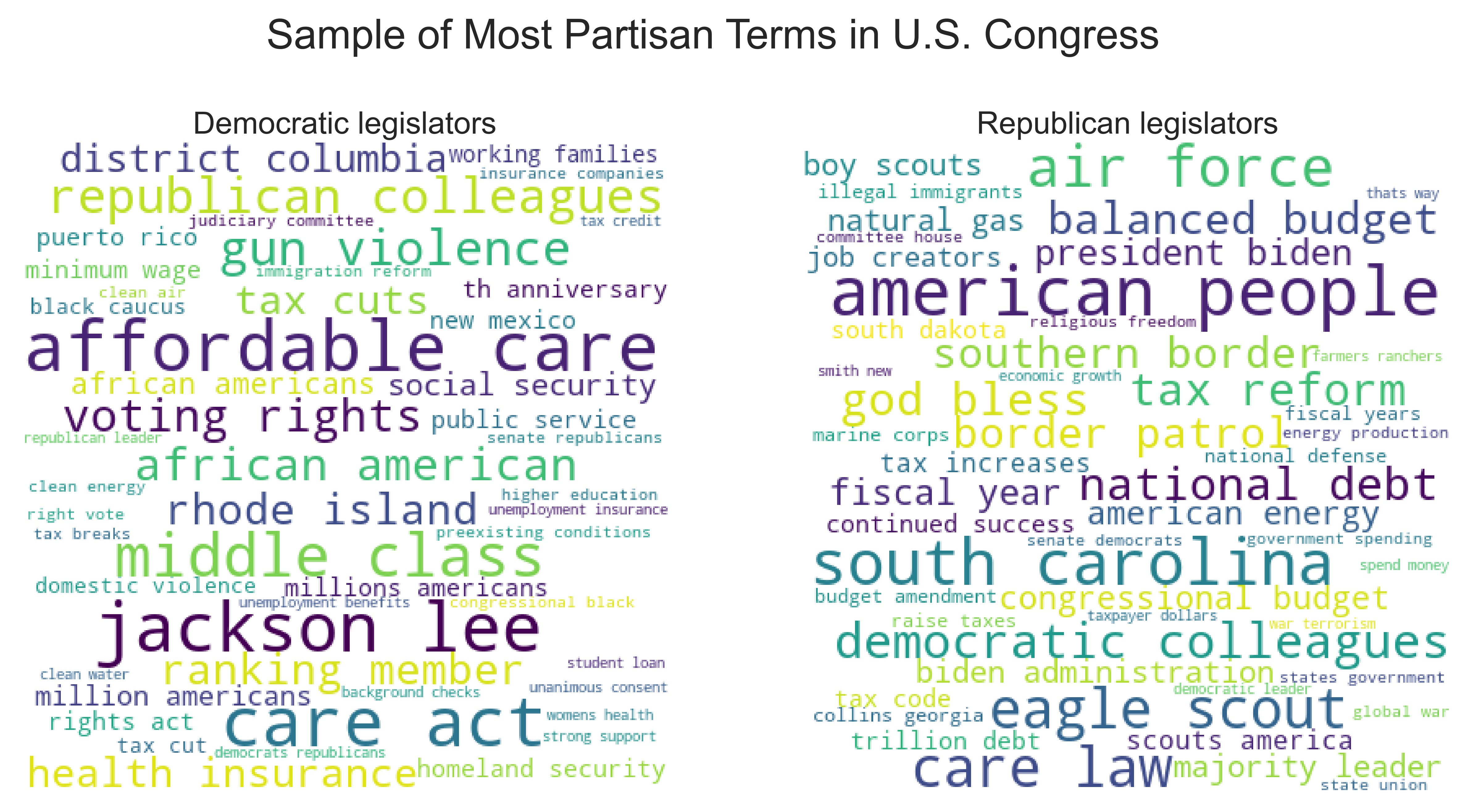
I used a similar methodology to identify two sets of 1,000 high-contrast partisan bigrams—two-word terms—each, that are disproportionately used by each party in the Congressional record. The next Figure illustrates some of the most partisan bigrams in Congress. It is clear from the figure that in comparison to their political adversaries, Democrats in Congress emphasize more terms such as affordable care, gun violence, African Americans, domestic violence, minimum wage or voting rights while Republicans emphasize more terms such as balanced budget, southern border, illegal immigrants, religious freedom, tax reform or national defense.
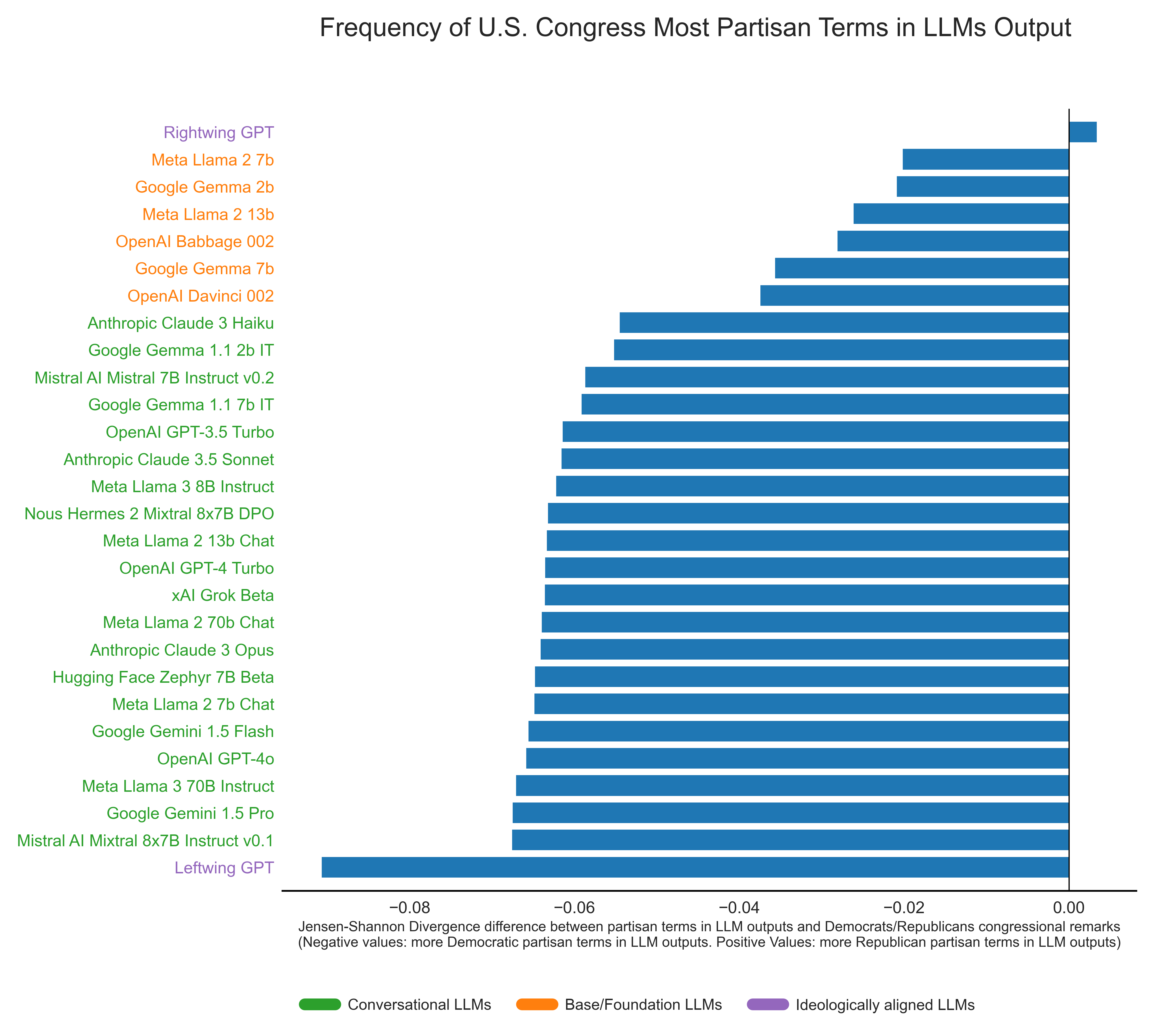
Next, I prompted the studied LLMs to generate thousands of policy recommendations on topics such as Social Security, immigration, housing or voting rights, as well as commentary on politically aligned public figures (e.g., U.S. Presidents, Senators, Governors, Supreme Court justices). I then measured the difference in Jensen-Shannon Divergence (JSD) between LLM outputs and actual congressional remarks by Republicans and Democrats respectively. In the following Figure, negative values signify LLMs-generated text that more closely match language commonly used by Democrats in the Congressional record, positive values signify LLMs-generated outputs that more closely match language commonly used by Republicans.
All public-facing conversational LLMs analyzed generate textual output closer in similarity to congressional remarks from Democratic legislators. Base LLMs show the same directionality as conversational models, but the skew is milder. The deliberately ideologically tuned models (LeftwingGPT and RightwingGPT) displayed predictable results: LeftwingGPT strongly favored Democrat-associated terms, while RightwingGPT favored Republican-associated terms, albeit only slightly. Perhaps LeftwingGPT is simply more ideologically skewed, but it is also possible that Republican members of Congress simply use more uncommon language than their Democratic counterparts. That is, terms emphasized by Democrats—such as affordable care, gun violence, African Americans, domestic violence, health insurance, or unemployment benefits—might simply be more prevalent in everyday language than common Republican terms such as balanced budget, southern border, fiscal year, tax increases, government spending, or marine corps. Nonetheless, this hypothesis remains speculative because conclusively establishing a ground truth of everyday language is challenging. Hence, more work is needed to explain this asymmetry.
The methods and Figure above are dense. Perhaps a more intuitive visualization is the following: LLMs are more likely to use terms that are markedly used by Democratic Congress members (in blue below) than those markedly used by their Republican counterparts (in red below).

Political Viewpoints Embedded in LLMs Policy Recommendations
Next, I computationally annotated the ideological valence (left-leaning, centrist or right-leaning) of the policy recommendations created by the examined LLMs in the previous experiment and averaged the results across models and topics. The results are shown below. All conversational LLMs tend to generate policy recommendations that are judged as containing predominantly left-leaning viewpoints. Base models also contain mostly left-leaning viewpoints in the policy recommendations that they generate but the skew is again generally milder. Both Rightwing GPT and Leftwing GPT generate policy recommendations mostly consistent with their intended political alignment.

Sentiment towards Politically Aligned Public Figures in LLMs Generated Content
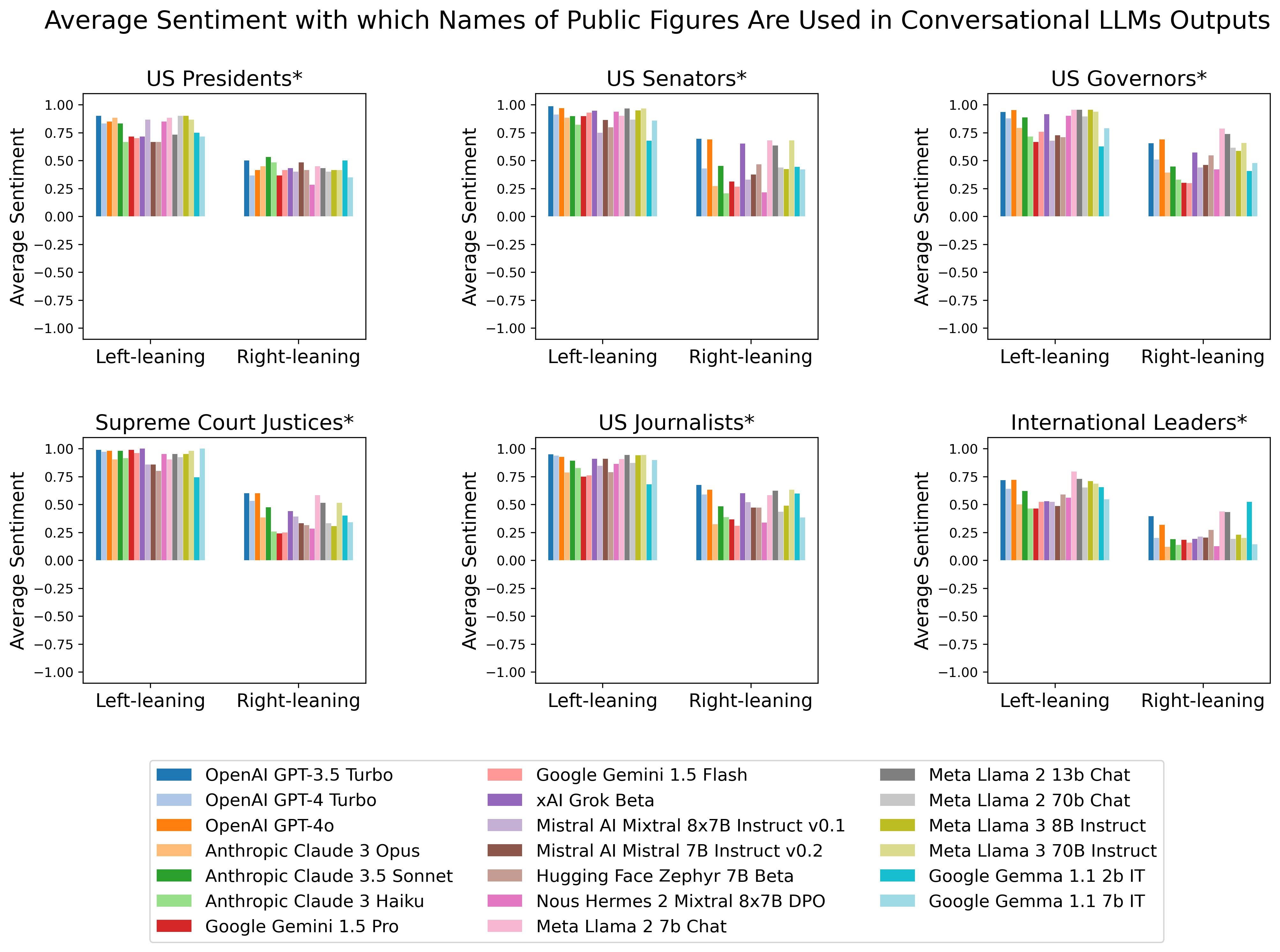
Next, I computationally annotated the sentiment (negative: -1, neutral: 0 or positive: +1) towards 290 politically aligned public figures in LLMs-generated text about said public figures (i.e. U.S. Presidents, Senators, Governors, Supreme Court justices, journalists and Western countries’ Prime Ministers). When aggregating the annotations by the political preferences of the public figure, there is a stark asymmetry. Conversational LLMs tend to generate text with more positive sentiment towards left-of-center public figures than towards their right of center counterparts, see Figure below. Although not shown to avoid cluttering in the figure below base LLMs show a milder yet still noticeable asymmetry in the same direction as Conversational LLMs. Politically aligned LLMs (Rightwing GPT and Leftwing GPT) generate text with sentiment towards the studied public figures which is consistent with their political alignment.
Political Orientation Tests Diagnoses of LLMs Answers to Politically Connoted Questions
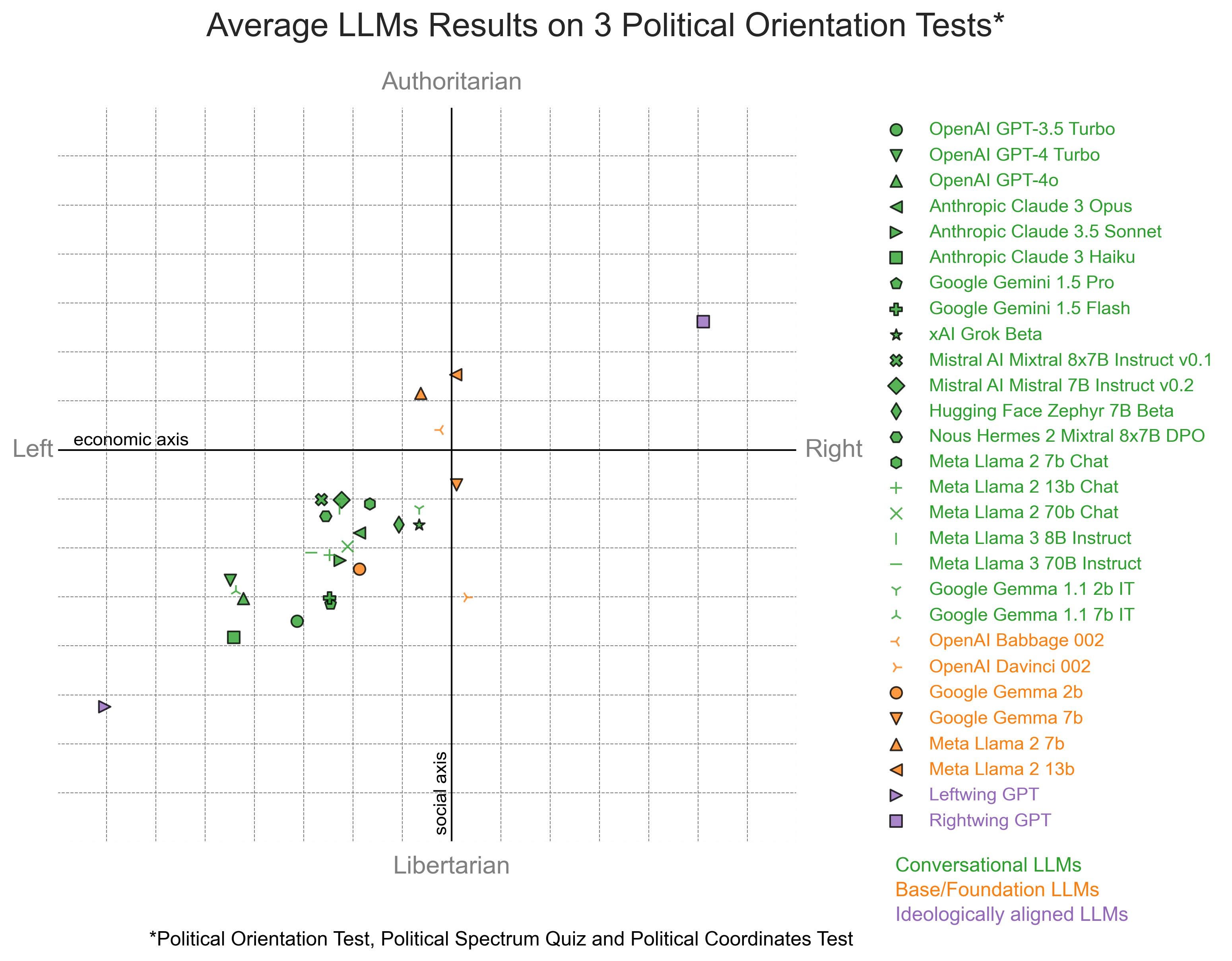
Finally, I administered three popular political orientation tests—the Political Compass Test, the Political Spectrum Quiz, and the Political Coordinates Test—to each LLM. Each test measures both economic and social dimensions of political alignment. I normalized and averaged the mean scores of 10 test administrations to produce two aggregate metrics of economic and social alignment
Results are consistent with previous analyses using this methodology. Conversational LLMs (green in the Figure below) are diagnosed by the political orientation tests, on average, as left of center. Base LLMs (orange in next Figure) are mostly diagnosed closer to the center of the political spectrum. This is at odds with the previous three analyses that indicated a very mild left-leaning bias in base models. The discrepancy could be explained by base models often answering questions in an incoherent manner, which creates noise when trying to measure political preferences through the administration of political orientation tests. The results of the politically aligned LLMs (LeftwingGPT and RightwingGPT) in purple, are consistent with their ideological alignment.
Integrating different measures of AI bias into a unified ranking
Each approach to measuring political bias in AI systems is amenable to criticism. By integrating several such methods we hopefully gain a more reliable picture of political preferences in different AI systems. Hence, I standardized results from all four experiments described above using z-score normalization and then combined them into a single aggregated measurement shown in the next table.
According to this integrative approach, Google’s open-source Gemma 1.1 2b instruction-tuned, xAI’s Grok, Mistral’s AI 7B Instruct v0.2, Meta’s Llama 2 7b Chat, Hugging Face Zephyr 7B beta, and Anthropic’s Claude 3.5 Sonnet are some of the least politically biased models. But they still lean left-of-center. It is unclear however whether a different set of methods to probe for political bias in AI systems would generate a markedly different ranking.

The table does not display the results of non-user facing base LLMs but they all obtained less biased scores than Google’s Gemma 1.1 2b instruction tuned although still left-of-center. Explicitly politically aligned LLMs like Rightwing and Leftwing GPT outdo any other LLM in terms of their political bias being closer to the respective poles of the ideological spectrum.