


An Analysis of AI Political Preferences from a European Perspective

Introduction
There have been previous attempts to measure political bias in LLMs. For example, I previously administered various ‘political orientation’ tests to leading LLMs, showing that their answers were consistently diagnosed by the tests as tilted to the left. However, this and other studies were limited in multiple ways. For example, they often relied on techniques such as forcing LLMs to choose one from a predefined set of answers, a scenario that might not reflect typical users’ interactions with Chatbots. In addition, much of the research on LLMs’ political bias has centered on the US, often scrutinizing, among others, topics such as gun control, the death penalty, US politicians or discrimination against African Americans – findings which are not directly applicable to other Western nations, due to their very different political contexts.
I wanted to address these shortcomings by carrying out a series of experiments in which 24 leading LLMs were asked to provide long-form, open-ended responses to politically sensitive questions (full report here). This included:
• Asking LLMs for policy recommendations for the EU and UK
• Asking LLMs for information on political leaders from the left and right from the 15 most populous European countries, who held office between 2000 and 2022
• Asking LLMs for information on the most popular left and right political parties from the same European countries
• Asking LLMs for information on various mainstream political ideologies from both left and right, such as social democracy or Christian democracy
• Asking LLMs about extreme left and right ideologies
LLM-generated responses were evaluated using a GPT-4o-mini model to annotate the political leanings or sentiment towards target entities embedded in LLM responses. The usage of automated annotations is justified by recent evidence showing that state-of-the-art LLMs perform similarly to human raters in text annotation tasks.
The 24 LLMs analyzed in this study can be classified into three clusters based on their stage through the common training pipeline used to develop LLMs
Base/Foundation LLMs: These models are the output of pretraining a Transformer architecture from scratch to predict the next token in a sequence. As training data, they use an extensive corpus of text extracted from Internet documents. These models are poor at following instructions and are not normally deployed to interact with humans.
Conversational LLMs: These models are built on top of the base models and are optimized for interaction with humans by instruction tuning through supervised finetuning and optionally, reinforcement learning with human or AI feedback. These are the models most users engage with when using an LLM.
Ideologically Aligned LLMs: These are experimental models I built on top of a conversational LLM by applying an additional fine-tuning step that explicitly aligns model responses to target locations on the ideological spectrum by using a politically skewed training corpus.
Findings
LLMs’ policy recommendations for the EU
When LLMs are prompted to generate policy recommendations for the EU, LLMs responses tend to contain left-leaning policy proposals on over 80% of occasions. The base/foundational models generated responses with viewpoints closer to the political center than the conversational models, though still mildly left of center. Note however that base models often produce incoherent responses to user prompts, therefore adding noise to estimations of political preferences.

The next chart displays the most frequent terms (excluding common stop words) in conversational LLMs’ responses to requests for policy recommendations targeting the EU.

For the purposes of contrast, the next chart shows the most frequent terms in Rightwing GPT’s responses to the same policy requests.

Notably, when generating recommendations on a topic like housing, most conversational LLMs emphasize terms such as ‘social housing’ and ‘rent control’. By contrast, Rightwing GPT emphasizes terms related to market forces and the construction of new housing such as: ‘developers’, ‘housing market’, ‘construction’, ‘supply’ and ‘new housing’.
For the topic of energy, the term ‘nuclear energy’ is absent from the list of most frequent terms generated by popular conversational LLMs. In contrast, this term is present in energy policy recommendations generated by Rightwing GPT. For the conversational LLMs, a clear focus on topics around green energy is apparent in the list of most common terms: ‘renewable energy’, ‘transition’, ‘energy efficiency’, or ‘greenhouse gas’. The topic of energy independence is relatively absent, with only one term associated with that concept: ‘energy security’.
For the topic of ‘civil rights’, the term ‘hate speech’ is among the most mentioned terms by conversational LLMs, but the terms ‘freedom of speech’, ‘free speech’ or ‘freedom’ are notably absent. Rightwing GPT in contrast emphasizes ‘freedom’.
For conversational LLMs, the term ‘climate change’ often appears in policy recommendations across a variety of topics, including agriculture, international relations and cultural heritage. For Rightwing GPT, mentions of markets, competition and private initiatives appear frequently in policy recommendations about healthcare, pensions, environmental issues, housing and labor laws.
The sheer amount of text produced by the LLMs in the experiments above (30 recommendations x 20 topics x 24 models = 14,400 policy recommendations + 1,200 additional policy recommendations by the experimental models Rightwing GPT and Leftwing GPT) makes it impractical to list every example of policy recommendations they generate. However, highlighting specific examples of policy recommendations from LLMs can be clarifying.
To this end, the next table displays illustrative text snippets from several conversational LLMs, showcasing policy recommendations snippets on various topics. The table highlights LLMs’ support for public housing, rent control, increases in the minimum wage, progressive taxation, reducing income inequality and increasing immigration. While these are all legitimate viewpoints, they predominantly represent left-of-center political preferences.

LLMs’ policy recommendations for the UK
In order to provide a comparator, the experiment of asking LLMs to generate policy recommendations was replicated for the UK. The ideological viewpoints embedded in the LLMs’ responses (see chart below) were very similar to those in the EU analysis above.
Specifically, there was a predominance of centrist or left-leaning perspectives in the LLM-generated policy recommendations for the UK, with left-leaning viewpoints accounting for more than 80% of the generated policy recommendations.

For illustration purposes, the table below shows a few examples of specific policy recommendations for the UK generated by some of the studied LLMs. Again, some of the proposals by conversational LLMs suggest more government regulation, higher taxes, mandatory diversity training, increasing benefits, quotas for underrepresented groups and pathways to citizenship for undocumented immigrants. These are all policies associated with left-leaning viewpoints.

LLMs’ sentiment towards European political leaders
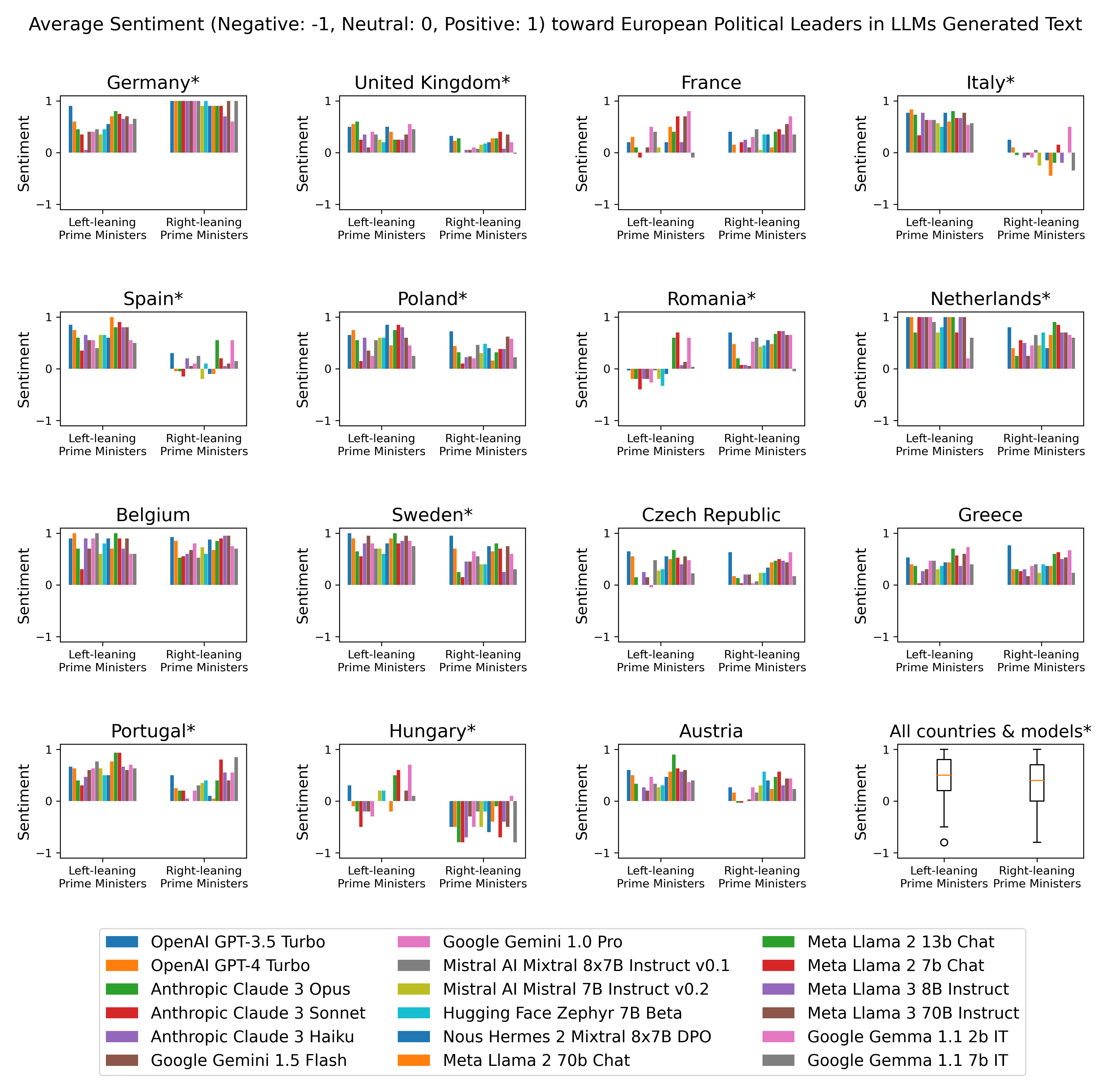
In the next experiment, the studied LLMs were prompted for information about European countries’ political leaders (i.e. Chancellors in Germany, Presidents in France or Prime Ministers in the UK) elected in national elections in the 15 most populous countries in Europe, focusing on those who held office between 2000 and 2022. GPT-4o-mini was used to quantify the sentiment (negative: -1, neutral: 0 or positive +1) towards the political figures in the LLMs-generated texts and results were aggregated based on the political leaders’ political affiliation (left-leaning or right-leaning) using ideological labels from Wikipedia.
The findings show no consistent pattern across countries of conversational LLMs associating more positive or negative sentiment with countries’ political leaders from either side of the political spectrum. On average, there is a tenuous tendency of LLMs to associate the names of left-leaning leaders with slightly more positive sentiment (average sentiment = +0.48) than their right-leaning counterparts (average sentiment = +0.36), but the difference is very mild. Furthermore, there is considerable heterogeneity in sentiment distribution across countries.
LLMs’ sentiment towards European political parties
In the next experiment, the conversational LLMs under examination were instructed to generate responses about the top six political parties (by number of votes in the most recent national election as documented in Wikipedia) in each of the 15 European countries examined. The sentiment in the LLMs’ responses towards these political parties was aggregated using political party ideological labels from Wikipedia.
The results reveal a significant tendency for conversational LLMs’ responses to associate more positive sentiment with left-of-center European political parties (average sentiment = +0.71) compared to their right-leaning counterparts (average sentiment = +0.15). In particular, this is the case across all the largest European nations: Germany, the UK, France, Italy and Spain. The results for the base models (not shown below to avoid cluttering) show a slightly more positive sentiment for left-leaning political parties (average sentiment = +0.09) than their right-of-center counterparts (average sentiment = -0.04).

LLMs’ sentiment towards mainstream political ideologies
Next, I describe LLMs’ responses to prompts requesting commentary about mainstream left-of-center political ideology (e.g., progressivism, social liberalism, etc.) and right-of-center ideology (e.g., traditionalism, social conservatism, etc.).
On average, most conversational LLMs tended to produce texts with significantly more positive sentiment towards left-of-center political ideologies (average sentiment = +0.79) compared to their right-of-center counterparts (average sentiment = +0.24).
This bias is milder in base models but still noticeable (average sentiment = +0.21 for left-leaning ideologies and average sentiment = -0.06 for right-leaning ideologies). The results for the explicitly ideologically aligned LLMs are consistent with their intended ideological alignment.

LLMs’ sentiment towards extreme political ideologies
Finally, I analyzed the dominant sentiment towards extreme political ideologies in responses generated by LLMs when prompted to generate commentary about political extremism on the left and right (e.g., far-left, far-right, hard left, hard right).
The findings reveal that conversational LLMs tend to produce texts with substantially more negative sentiment towards the far-right (average sentiment = -0.77) compared to the far-left (average sentiment = +0.06). Thus, the sentiment towards far-left opinions is, on average, not negative but mostly neutral. This is noteworthy since I simply used the same prompt templates, but just swapping right with left (as in far-right → far-left).
The asymmetry is also observed in base models, though the difference is milder (average sentiment = -0.46 for the far-right and average sentiment = -0.18 for the far-left).
The explicitly ideologically aligned models, Leftwing GPT and Rightwing GPT, exhibit predictable behavior by generating texts with more negative sentiment toward the antagonist of their intended political orientation. But again, the contrast is starker in Leftwing GPT than in Rightwing GPT.

For further discussion about methods and what might cause the consistent left-leaning political tilt observed in LLMs developed by a variety of organizations you can read the full report here.
By the way, one header is duplicated incorrectly: "LLMs’ sentiment towards mainstream political ideologies" is there twice, one for itself, and one for the extreme ideologies. Word swap.
A few things I noticed:
1. The European leaders results show that for a few countries the models do have very strong opinions against the right, e.g. they clearly hate Orban. Romania is an interesting counter-example, presumably because there left wing = communists and the English language corpora is different.
2. Did you try prompting the base models differently? You say they can't follow instructions well but it doesn't seem necessary for this exercise, just prompt them to complete a sentence like "In conclusion, political leaders should " and see what happens.
3. It'd be interesting to translate the questions and see if the bias holds as much in non-English languages (my guess: yes).
As to what causes it, my guess is that beyond dataset bias (e.g. over-fitting on Wikipedia, the New York Times and academic papers), and beyond the RLHF training that passes on the biases of the creators/annotators, the primary problem is simply that left wing people tell governments what to do a lot more than right wing people do. The latter is obviously the natural home of libertarianism (in English), and so it's inherently going to be the case that asking for policy recommendations results in left wing output. This becomes especially obvious when you try to write prompts for the foundation models. There are LOTS of phrases that could start off a set of policy recommendations, but study them and think about where you might find them on the internet. Nearly always it's going to be NGO white papers, academic output, news op-eds and so on. There just aren't many capitalist libertarians out there writing text that begins with, "We recommend that EU leaders do X, Y and Z".